Table des matières
2. Les containers et Docker
2.1. Principes des containers
Comme présenté au chapitre précédent, la conteneurisation permet une forme légère de virtualisation grâce au partage du noyau du système d’exploitation de l’hôte. On parle également de virtualisation au niveau de l’OS (OS-level virtualization)

Un container est un environnement d’exécution isolé pour une application, contenant tout ce qui est nécessaire à l’exécution de cette dernière (exécutables, bibliothèques, dépendances, fichiers de configuration). Il tourne en mode utilisateur.
L’isolation du container permet la limitation des accès et des ressources dédiées à l’application, ce qui apporte une protection entre l’hôte et les containers, et entre les différents containers.
Le fait que le container contienne toutes les dépendances de l’application permet la portabilité : le container peut tourner facilement sur des environnements différents tant que ces derniers sont pourvu du noyau adéquat : Serveur “bare-metal”, infrastructure cloud, environnement de développement, …
Enfin, par leur légèreté, les containers permettent un déploiement et une adaptation à la charge rapide, puisqu’ils peuvent être démarrés et arrêtés rapidement.
2.2. Containers et images
Les images [1,2] sont un élément essentiel dans l’écosystème des containers, puisqu’il s’agit de fichiers légers, portables et interopérables contenant tous les éléments nécessaires au démarrage d’un ou plusieurs conteneurs dans un cadre applicatif spécifique. Une image de container est donc un “package” contenant les libraires, fichiers et éléments de configuration systèmes. Une image peut être utilisée sur différents systèmes ou différentes machines. Depuis une image, un ou plusieurs containers peuvent être démarrés. Ils auront alors tous un environnement d’exécution de départ identique.
La plupart des formats d’image de conteneur fonctionnent sur base d’un système de fichiers en couches (Layered File System ou Union File System) : l’image est une superposition de couches par dessus une couche de base. L’intérêt de cette technique est que les couches peuvent être partagées entre images. Par exemple, depuis une même couche de base unique définissant l’image d’un système Ubuntu, il est possible de rajouter des couches pour en faire une image de serveur web, ou bien, en rajoutant d’autres couches, un serveur de base de données.
Toutes les couches d’une image sont accessibles uniquement en lecture, à l’exception de la couche supérieure, qui, une fois un container démarré sur base de cette image, est également accessible en écriture afin de permettre l’exécution du container.
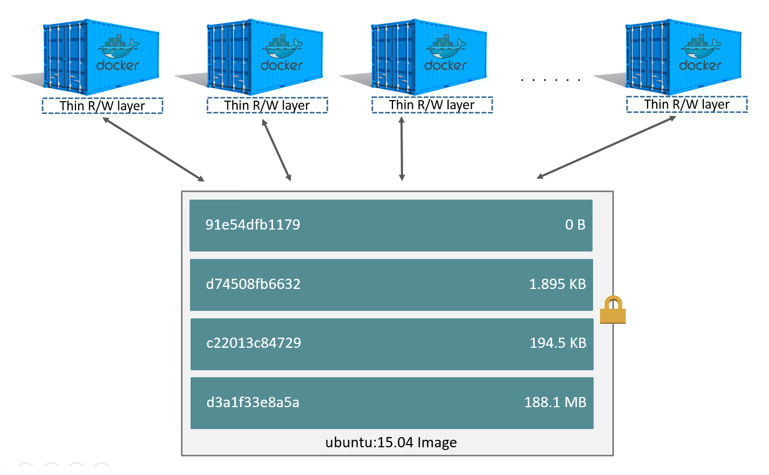
Les images peuvent être construites sur base de fichiers descriptifs (Dockerfile, ou containerfile), qui indiquent l’image de base à utiliser, et les opérations à effectuer par dessus cette image de base. Chaque opération génère une nouvelle couche, “personnalisant” ainsi l’image de départ en fonction de l’application souhaitée.
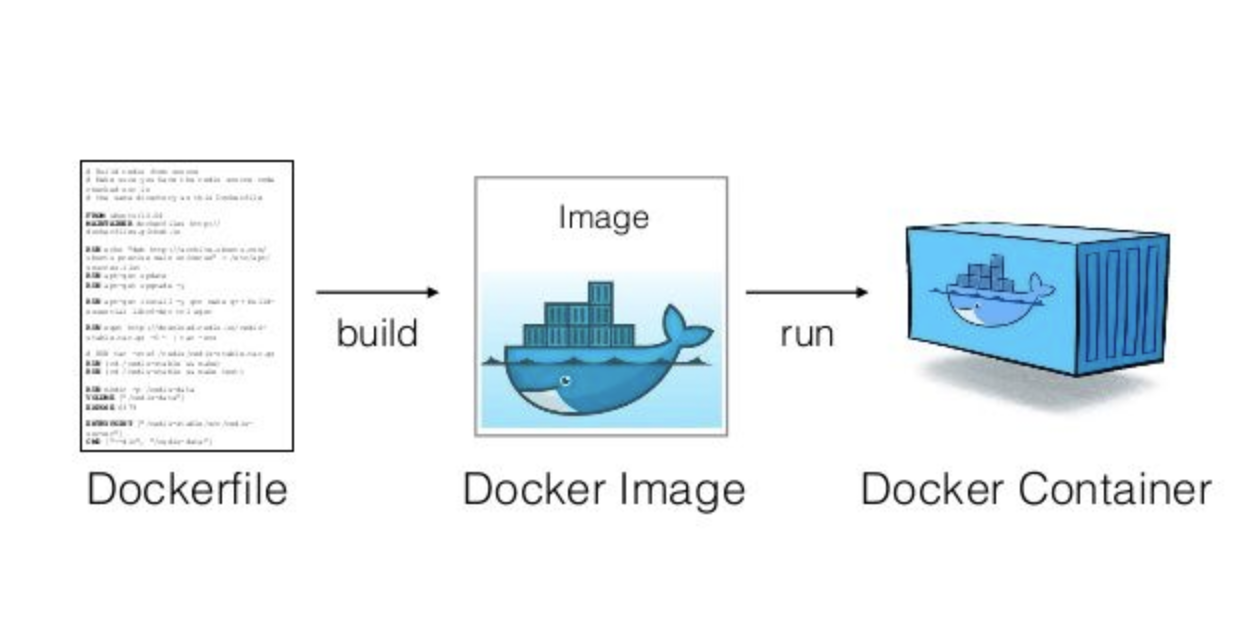 <figcaption>
<figcaption>
2.3. Historique des containers [4,5] [facultatif]
2.3.1. De Chroot aux LXC
Le principe de l’isolement applicatif remonte à 1979, où la commande “chroot” apparait avec la version 7 de Unix. Cet appel système permet de changer le root directory visible par un processus et ses enfants. Cela permet de restreindre la visibilité du système de fichiers par le processus à la nouvelle racine ainsi définie. On commence alors à parler de “jail” pour désigner cet environnement d’exécution isolé.
Néanmoins, les jails crées par l’appel système chroot peuvent être contournées, et ne sont donc pas des solutions sécurisées. Il faut notamment les limiter aux processus non-root. En 1999, FreeBSD a introduit une nouvelle commande “jail” qui, elle, permet une véritable isolation des processus, leur attribuant entre autres un adressage IP spécifique. Cette technologie a été notamment exploitée à l’époque par de petits fournisseurs de services, pour fournir des environnements dédiés à leurs clients.
Dans les années qui ont suivi, d’autres technologies sont apparues, étoffant les fonctionnalités de ces environnements : Partition et contrôle des ressources, snapshot, … Parmi ces technologies, on trouve les Linux VServers, les Solaris Containers, OpenVZ, …
En 2006, Google introduit les “Process Containers”, renommés plus tard “cgroups” [6] lors de leur intégration dans le kernel Linux. Les cgroups permettent de limiter et contrôler l’utilisation des ressources système à l’échelle d’un groupe de processus spécifique (CPU, mémoire, accès disque, accès réseau).
Les cgroups sont un des éléments centraux de LXC (LinuX Container), qui est la première technologie complète de conteneurisation intégrée au noyau Linux. LXC exploite, en plus des cgroups, les namespaces Linux [6,7,8] : ces derniers sont une alternative évoluée de chroot.. Ils permettent de séparer et d’isoler, non plus uniquement le système de fichiers, mais l’ensemble des ressources systèmes, en fournissant aux processus ainsi isolés une vue différente de ces ressources/espaces de noms.
- espace de nom pour les systèmes de fichiers (points de montage)
- espace de noms des processus (PID)
- espace de noms réseau (interfaces, tables de routage, …)
- espace de noms des IPC (inter-process communication)
- espace de noms des utilisateurs (UID, GID)
- espace de noms des hostnames et des noms de domaine
2.3.2. L’essor des containers : De Docker à Kubernetes
En 2013, la première version de Docker apparait. Dans un premier temps, celle-ci repose sur les containers Linux (LXC). Plus tard, Docker remplacera l’utilisation de LXC par sa propre librairie, libcontainer, pour accéder aux fonctionnalités Linux telles que les cgroups et les namespaces. Cette librairie évoluera ensuite vers runc, dans le cadre de l’OCI (voir plus bas).
La spécificité de Docker est l’ensemble de l’écosystème qu’il propose pour la gestion des containers : les images, le registre Docker Hub, … ainsi qu’un ensemble d’API pour interagir avec ces éléments.
Les années 2010 ont vu l’expansion de l’utilisation des containers, mais également l’apparition des questionnements concernant leur sécurité : mise en évidence de vulnérabilité, apparition des pratiques DevSecOps, … Des solutions apparaissent depuis pour améliorer la sécurisation des containers, mais la sécurité doit, comme toujours, rester une préoccupation majeure des utilisateurs.
Fin des années 2010, l’orchestrateur Kubernetes, permettant le pilotage et la gestion distante et unifiée de containers sur différents types d’hébergement, est massivement adopté dans l’industrie, dans le cadre de la mise en oeuvre d’applications Cloud et d’architectures micro-services. Depuis 2017, en plus de sa solution d’orchestration propre Docker Swarm, Docker est compatible avec Kubernetes.
Kubernetes utilise le terme “Pod” pour définir une unité d’exécution d’application, à savoir un container. Les Pods tournent sur des Nodes, qui sont des machine-hôtes pouvant exécuter des containers. Les Nodes sont gérés à distance par le Kubernetes Master, qui se chargera de contrôler le démarrage des Pods, de surveiller leur exécution et d’ajuster à la demande les ressources disponibles en déployant ou en arrêtant des pods.

2.3.3. Standardisation des containers et utilisation en dehors de Linux
Ces dernières années, des initiatives de standardisation des technologies de conteneurisation ont commencé à voir le jour, notamment dans le cadre de l’Open Container Initiative (OCI) [11]. Cette dernière propose actuellement deux spécifications :
- Une pour l’exécution des containers (runtime), à savoir une définition de ce qu’il faut démarrer comme container, avec les spécifications des ressources et de l’isolation demandées,
- et une autre pour les images des containers.
En plus de ces spécifications inter-opérables, l’OCI propose des implémentations de références, dont runC pour Linux, dérivée du libcontainer de Docker.
Les containers sont également utilisables sur d’autres plateformes que Linux/Unix. Différents cas de figure sont possibles :
- Pour utiliser des conteneurs Linux sur un système Windows ou MacOS, des solutions basées sur l’utilisation d’une machine virtuelle intermédiaires ont été proposées, dans le cadre de la distribution Docker Desktop (qui contient par ailleurs une interface graphique de gestion des objets Docker).
- Sous Windows, soit WSL2 (Windows Subsystem for Linux) est utilisé comme hôte Linux, soit une VM Linux légère (appelée MobyVM) est lancée via Hyper-V, selon la configuration et le choix de l’utilisateur.
- Sous MacOS, Docker tourne dans une VM au dessus d’HyperKit, qui est une boîte à outils exploitant l’hyperviseur natif de MacOS
- Il existe également des conteneurs Windows, permettant donc de conteneuriser des applications Windows. L’implémentation des containers Windows utilise des principes similaires à la conteneurisation Unix pour isoler les applications, mais sur base des fonctionnalités spécifiques au noyau Windows. Les containers Windows ne tournent actuellement que sur des hôtes Windows.
2.4. Fonctionnement et écosystème Docker [facultatif]
Comme mentionné plus haut, Docker est un outil de conteneurisation initialement disponible sous Linux. Bien qu’étant au départ une interface permettant la gestion de container LXC, Docker est depuis lors passé sur son propre driver de conteneurisation, libcontainer, devenu par après runc dans le cadre de l’OCI. Docker a également adopté, après en avoir été à l’initiative, le démon containerd [9], qui gère l’ensemble du cycle de vie des containers, depuis la récupération de l’image sur d’éventuels registres distants jusqu’à la gestion des réseaux et des volumes de données. containerd est un élément de gestion de haut niveau de containers respectant la spécification OCI, tandis que runC est une implémentation bas niveau permettant l’exécution des containers.
Le driver runC interagit avec les éléments du kernel Linux permettant la mise en oeuvre de containers : Les cgroups et les namespaces, déjà mentionnés plus haut, mais également les capabilities Linux, permettant de contrôler plus finement les droits des processus que ce qui est permis par les traditionnels modes user (non-privilégié) ou root (privilégié), ou encore les modules de sécurité SELinux, Apparmor, ou les firewalls systèmes pour le routage et le mapping de ports.
La force de Docker réside dans les outils qu’il propose autour du runtime des containers, et aux API qui y sont liées.
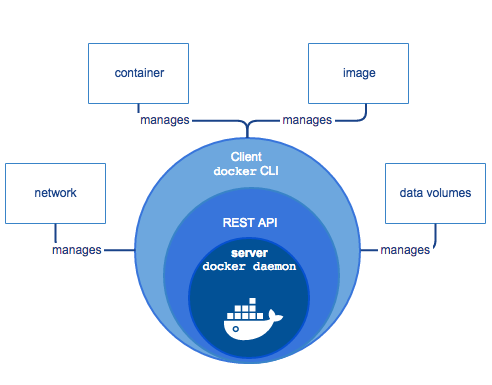
Dans l’image ci-dessous, on observe trois éléments :
- Le client Docker : Il s’agit de l’interface en ligne de commande. Elle tourne généralement sur l’hôte Docker lui-même, et interagit avec les hôtes docker via une API vers le démon Docker.
- L’hôte Docker : C’est une machine sur laquelle tournent des containers Docker. Différents éléments vont intervenir : des images, disponibles sur le système de fichiers (ou pas), des containers en cours d’exécution ou stoppés, et un logiciel de gestion : Le démon Docker (dockerd). Le démon Docker gère les images, les containers, mais également les réseaux et les volumes utilisés par ces derniers, sur base des instructions reçue sur son API. C’est le démon Docker qui utilisera la librairie containerd mentionnée plus haut, qui à son tour utilisera éventuellement runC pour créer, démarrer ou stopper les conteneurs.

- Un registre d’images : c’est un repository distant depuis lequel il est possible de télécharger des images Docker. Le Docker Hub est un registre public géré par Docker.

Lorsqu’on installe Docker sur une machine, on installe en pratique le Docker Engine, qui est une application client-serveur comprenant le démon docker (dockerd), le client docker (docker), et l’API entre ces deux éléments. Le Docker Engine gère les quatre types d’objets Docker : Les containers, les images, les réseaux et les volumes.
Bibliographie
[1] Documentation Docker, Getting Started, consulté en fév. 2023
[2] Ravikanth Chaganti, Understanding container images - the fundamentals, oct. 2022, consulté en fév. 2023
[3] Documentation Docker, About storage drivers, consulté en fév. 2023
[4] Rani Osnat, Aqua Blog, A Brief History of Containers: From the 1970s Till Now, janv. 2020, consulté en février 2023
[5] IONOS Digital Guide, Alternative à Docker : aperçu des technologies de conteneurs, juil. 2019, consulté en février 2023
[6] Manoj s k, ITNEXT, chroot, cgroups and namespaces - an overview, mai 2018, consulté en fév. 2023
[7] Michael Kerrisk, LWN.net, Namespaces in operation, part 1: namespaces overview, janv. 2013, consulté en fév. 2023
[8] Linux Manual Page, namespaces(7), consulté en fév. 2023
[9] Michael Crosby, Docker blog, What is containerd? août 2017, consulté en fév. 2023
[10] KodeKloud blog, Docker vs. Containerd: A Quick Comparison (2023), consulté en fév. 2023 [11] The Linux Foundation Projects, Open Container Initiative
[12] Liz Rice, Containers from scratch, conférence GOTO 2018, consulté en fév. 2023